
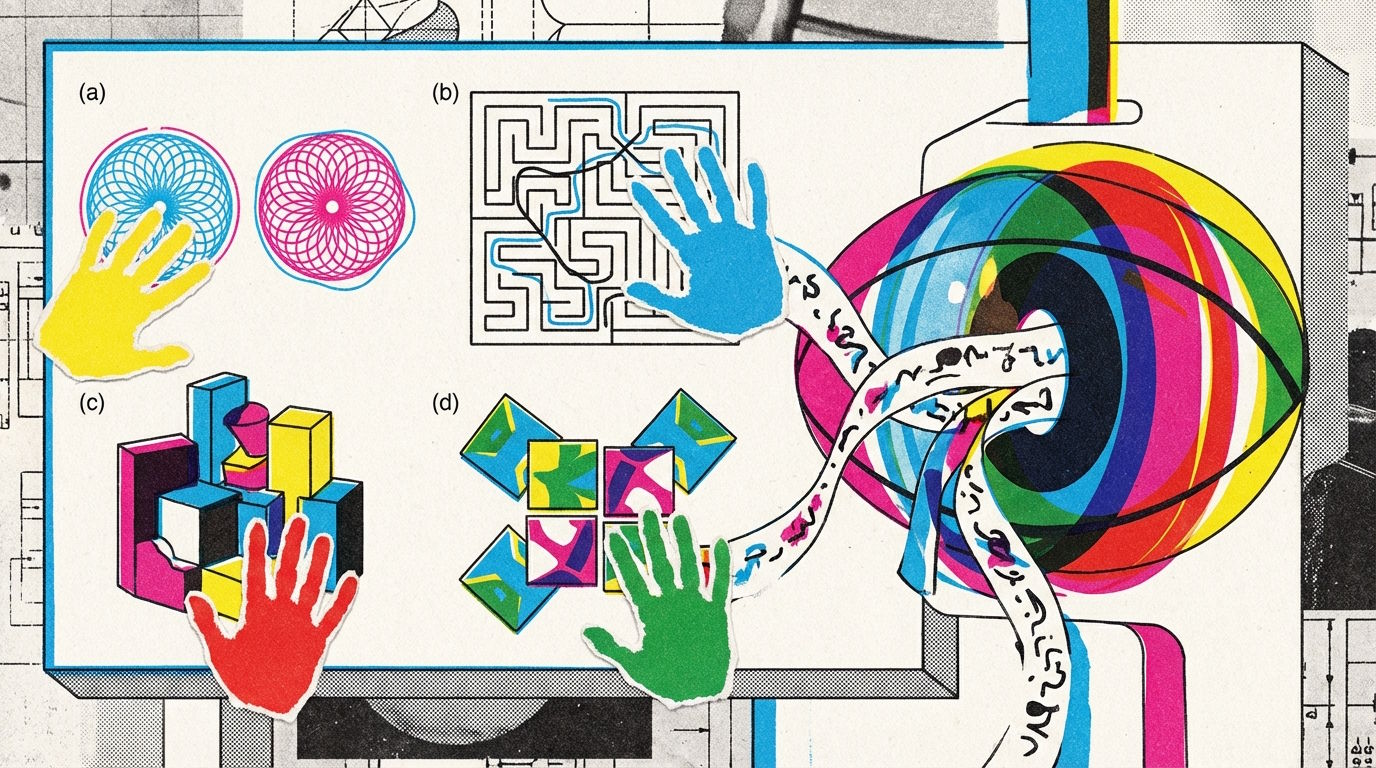
AI Models Lag Behind Toddlers in Basic Visual Understanding
A recent study has uncovered a critical shortfall in current artificial intelligence systems, particularly multimodal language models that combine visual and textual inputs. These AI models, despite their sophistication, are unable to perform fundamental visual tasks that toddlers master naturally at a very young age.
Visual Tasks Beyond AI’s Current Reach
The research emphasizes that even the best AI models struggle with recognizing and processing basic shapes, patterns, and spatial arrangements—tasks that children as young as two or three years old handle with ease. This gap reveals an essential difference between human cognitive development and AI capabilities.
While AI has made remarkable progress in language processing and complex problem-solving, its ability to interpret and interact with visual information remains limited. Tasks such as identifying simple geometric figures, navigating mazes, or assembling puzzles, which toddlers complete effortlessly, still pose significant challenges for AI.
Implications for AI Development and Everyday Use
The findings suggest that AI systems are not yet equipped to fully replace or replicate human perceptual skills, especially in real-world environments where visual comprehension is crucial. This limitation impacts applications ranging from autonomous vehicles to healthcare diagnostics, where accurate visual interpretation is vital.
Moreover, the study calls for a renewed focus on integrating developmental psychology insights into AI research to bridge the gap between human and machine perception.
Understanding AI’s Current Capabilities
Multimodal AI models are designed to process and understand information from multiple data sources simultaneously, such as images and text. However, the current generation of these models relies heavily on pattern recognition and large datasets rather than true visual reasoning.
As a result, they may misinterpret or oversimplify visual inputs, leading to errors that a toddler would unlikely make. This limitation underscores the complexity of visual cognition and the challenges AI must overcome to achieve human-like understanding.
Looking Ahead: Enhancing AI Visual Intelligence
Addressing these challenges requires interdisciplinary collaboration, combining advances in machine learning, cognitive science, and neuroscience. Improving AI’s visual reasoning capabilities could unlock new possibilities in education, robotics, and accessibility technologies.
In the short term, users and developers should be aware of these limitations when deploying AI systems in tasks involving visual comprehension, ensuring human oversight remains integral.
Fonte: ver artigo original
Related Articles
 Trump’s AI Executive Order Aims for Unified National Regulations but May Create Legal Challenges for Startups
Trump’s AI Executive Order Aims for Unified National Regulations but May Create Legal Challenges for Startups Adobe, Qualcomm, and Humain Collaborate to Advance AI Solutions for Arabic Content and the Middle East
Adobe, Qualcomm, and Humain Collaborate to Advance AI Solutions for Arabic Content and the Middle East AI Startups Dominate Venture Capital Funding with Promising Returns
AI Startups Dominate Venture Capital Funding with Promising Returns Study Finds Labeling Ads as AI-Generated Reduces Clicks by 31 Percent
Study Finds Labeling Ads as AI-Generated Reduces Clicks by 31 Percent

